结构化分析方法与系统分析中常用的工具
出处:按学科分类—工业技术 企业管理出版社《工程师手册》第982页(7030字)
1.结构化分析方法的基本思想
结构化分析方法(简称SA方法)是软件系统需求分析中最常用的方法,它是面向数据流的分析方法。
结构化分析方法的基本思想是采用由顶向下逐层分解的方式把一个大型系统分解成许多足够简单的基本部分。系统的分解和各部分之间的联系用数据流图来描述,系统中的数据以及数据流的加工用下列表达工具来定义。
(1)数据词典;
(2)结构化语言;
(3)判定表;
(4)判定树。
2.数据流图
数据流图是从数据传送和加工的角度,以图形方式描述数据处理过程的有力工具。
(1)数据流图的基本成分与其表示
数据流图的基本成分有加工、文件、源点或终点、数据流等4种,其含义与表示方法如下。
①加工 加工是对数据进行的操作。在数据流图中加工用圆表示,且每个加工分别以一个唯一的名字命名。通常,文件名按其实际意义加以命名。
②文件 这里的文件指暂时存储的数据。在数据流图中文件用直线段表示,每个文件分别以一个唯一的名字命名。通常,文件名按其实际意义取名。
③源点或终点 指数据流的源点或终点。在数据流图中源点或终点用方框表示,并据其实际意义加以命名。
④数据流 数据流由一组固定成分的数据组成。在数据流图中数据流用箭头表示。可以是从源点流向一加工的数据流,或从一加工流向另一加工的数据流,或从一加工流向终点的数据流,还有从一加工流向一文件或从一文件流向一加工的数据流。两个加工之间可有几个相互间并无任何联系,也不是同时流出的数据流。除流向文件或从文件流出的数据流外,对每个数据流应命名一个唯一的、易理解的名字。例如,图7.3.2-1中,数据流1是从源点流向加工1的数据流,数据流2是从加工1流向加工2的数据流,数据流3是从加工2流向终点的数据流,这些数据流可按其实际意义加以适当命名。图7.3.2-1中,还有从文件1流向加工1的数据流与加工2流向文件2的数据流,这些数据流可不用命名。
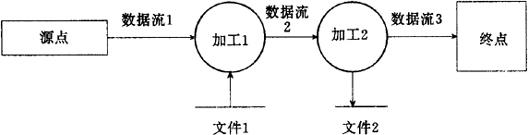
图7.3.2-1 数据流图示例
⑤辅助性符号 除以上4种基本成分外,在数据流图中还可用辅助性符号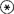 和
和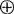 。
。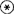 表示“与”,
表示“与”, 表示“或”。例如,在图7.3.2-2中使用了两个辅助性符号。图7.3.2-2表示,在执行加工P时要用到A1和A2两个数据流,加工P执行后输出B1或B2中的一个数据流。
表示“或”。例如,在图7.3.2-2中使用了两个辅助性符号。图7.3.2-2表示,在执行加工P时要用到A1和A2两个数据流,加工P执行后输出B1或B2中的一个数据流。
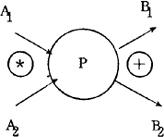
图7.3.2-2 采用符号 和④的示例
和④的示例
(2)分层的数据流图 对于一个大型系统,用一个数据流图来画出系统中所有数据流和加工将是一张庞大的复杂的图,很难理解。为此,可按由顶向下的原则逐步细化地分解系统的过程中画出一套分层的数据流图。分层的数据流图是易理解的表达图。一套分层的数据流图由顶层、中间层和底层组成。顶层是很抽象的,它只有一个图,它说明系统的边界,即系统的输入数据流和输出数据流。中间层给出了从抽象到具体的逐步细化的过渡。同一个中间层可有若干个图,每个图描述其上一层中对应的某个加工的分解,而该图中的各个加工又可在其下一层中再进一步分解。底层则由一些足够简单而不必再分解的基本加工组成。
图7.3.2-3示出一套分层的数据流图的一个示例。它分三层。顶层表示系统S的输入数据流为A和B,输出数据流为X。图0为中间层,它把系统S分解为3个加工(加工1、加工2、加工3)。加工1的输入为A,输出为C;加工2的输入为B,输出为D;加工3的输入为C和D,输出为X。底层有两个图(图1和图2)。图1把加工1又分为4个子加工(1.1、1.2、1.3、1.4),图2把加工2又分为3个子加工(2.1、2.2、2.3)。由于加工3足够简单而不需再细分,子加工1.1、1.2、1.3、1.4、2.1、2.2、2.3均因足够简单而不再细分。否则可再分解下去直到都足够简单为止。图0是图1和图2的父图,图1和图2是图0的子图。子图是父周的详细描述,父图是子图的抽象描述。在分层数据流图的描绘中应注意以下几个问题。
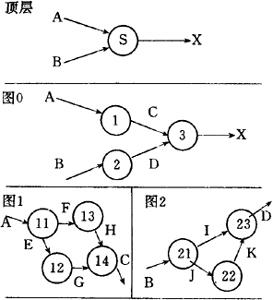
图7.3.2-3 分层的数据流图示例①为易理解起见,除顶层外的所有其他层的图与这些图中出现的加工均予以编号(每个加工除加工名外再加一个编号)。编号的规则是这样的:紧接顶层的中间层的图号为0,图0中的加工的编号分别为1、2、3、…。对于图0下的各层子图的编号分别取其父图中相应加工的编号,子图中的加工的编号由子图号、小数点、局部顺序号组成。例如,图1是对应其父图(图0)的加工1的子图,图1中的4个加工的编号分别为1.1、1.2、1.3、1.4;图2是对应其父图(图0)的加工2的子图,图2中的3个加工的编号分别为2.1、2.2、2.3。若加工2.2需进一步细分,则其相应子图的编号为2.2,该子图中细分的加工的编号分别为2.2.1、2.2.2、2.2.3、…。依此类推。
②子图的输入数据流、输出数据流应同父图中相应加工的输入数据流、输出数据流完全一致。例如,图1的输入数据流为A,其输出数据流为C,这同其父图(图0)中相应加工(加工1)的输入数据流为A,输出数据流为C是完全一致的。
③分层的目的是提高数据流图的可理解性。因此在分解中采取在不影响易理解性的基础上把一个加工分解成适当多个(n个)子加工。这样做法的好处是可适当减少分解的层数。n不宜过大,n也不宜过小。n过大则不易理解,n过小则分解的层数势必过多。一般以3<n≤7为宜。
3.数据词典
数据词典用来对数据流图中各成分的名字加以定义。一个数据词典由若干条目组成。有数据流、文件、数据项、加工4种类型的条目。
(1)数据流类型的条目 对于数据流类型的条目,要列出组成该数据流的数据项。例如:
数据流名:发票
组成:单位名+货名+货号+数量+单价+总计
此处的+表示“和”。该条目定义“发票”这个数据流由“单位名”、“货名”、“货号”、“数量”、“单价”和“总计”等6个数据项组成。
对于复杂的数据流,可用逐步分解的方式来定义。也就是说,其组成数据项还可作为一个条目再加以进一步分解。
(2)文件类型的条目 对于文件类型的条目,除了列出其记录的组成数据项外,还要指出文件的组织方式。例如:
文件名:价目
组成:货号+单价
组织方式:接货号递增排列
该条目定义“价目”这个文件的各记录由“货号”和“单价”两个数据项组成,该文件中各记录按“货号”递增顺序排列
(3)数据项类型的条目 对于不再分解的数据项,有的其名字本身已有很明确的含义(它是自定义的),无需再加以解释。有的则需对其数据值的类型、允许的取值等加以定义。例如:
数据项:帐号
值:00001~99999
该条目定义“帐号”这个数据项的值可以是从00001到99999之间的5位整数。
数据项:存期
值:1|2|3|5|8
此处的|表示“或”。该条目定义“存期”这个数据项的值可取1、2、3、5或8。
(4)加工类型的条目 对于加工类型的条目,要定义它的激发条件与加工逻辑。还要给出该加工的编号,以便与数据流图相互参照。例如:
加工名:开发票
编号:2.1
激发条件:收到订货单
加工逻辑:把“订货单”的“单位名”、“货名”“货号”、“数量”等数据项复制到“发票”的相应数据项中;按“订货单”的“货号”读“价目”文件的相应记录;把读得的“单价”复制到“发票”的“单价”中;令“发票”的“总计”=“单价”ד数量”。
(5)符号的约定 为表达的简便起见,在条目的定义中要用到一些符号,这些符号可以自己约定,尽量采用大家习惯的符号,以便易于为别人所接受。例如,前面的例子中用+表示“和”,用|表示“或”,用~表示取值范围的“到”。另外,还可用=表示“定义为”,用[]表示“任选”,用{}表示“重复”,等等。若约定=表示“定义为”,则“账号=00001~99999”这个条目表示“账号”这个数据项的值取从00001到99999之间的5位整数,“存期=1|2|3|5|8”这个条目表示“存期”这个数据项的值可取1、2、3、5或8。很明显,“发票=单位名+货名+货号+数量+单价+总计”这个条目表示“发票”这个数据流是由“单位名”、“货名”、“货号”、“数量”、“单价”和“总计”等6个数据项组成的。
4.结构化语言
结构化语言是一种带有一定格式的自然语言。它可用来对数据流图中的加工加以定义。结构化语言没有确定的语法,它没有保留字清单,可以灵活书写,只要遵守“无二义性”与“易理解”的原则,能明确地表达出“做什么”即可。
(1)顺序性操作 对于顺序性操作可用以下两种形式书写。
①形式1
〈执行事件1〉;〈执行事件2〉;…;〈执行事件n〉
②形式2
〈执行事件1〉
〈执行事件2〉
〈执行事件n〉
(2)条件性操作 对于条件性操作可用以下形式书写。
如果〈某条件满足〉则〈执行某事件〉
(3)重复性操作 对重复性操作可用以下3种形式书写。
①形式1
重复执行下列事件〈若干〉次:
…
…
…
②形式2
重复执行下列事件:
…
…
…
直到〈某条件满足〉为止
③形式3
当〈某条件满足〉时,重复执行下列事件:
…
…
…
5.判定表
判定表是用列表来描述或规定与条件组合相结合的各种动作的表达工具。在需描述的加工系由一组操作组成,而是否执行某些操作又取决于一组条件时,用判定表来写加工逻辑是比较方便的。图7.3.2-4示出一个判定表的示例。图7.3.2-4中,标记-表示任意,标记√表示要执行。
订货判定表
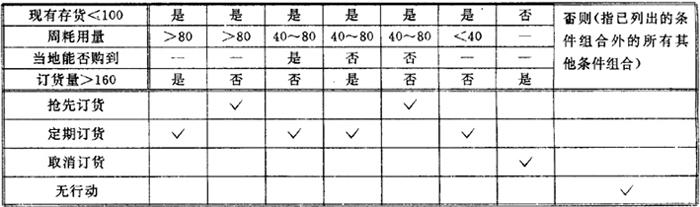
图7.3.2-4 一个判定表的示例
(1)判定表的组成部分 判定表通常被看作由4个重叠的部分组成,其中每个部分是判定表这个总矩形内的一个矩形。作为4个组成部分的各矩形的比例分配因情况而异。判定表的上半部称为条件部分,下半部称为动作部分,左半部称为根部(茬),右半部称为项目部分。通常,右半部又分若干栏,每一栏称为一个判定规则。由于重叠的缘故,判定表的左上部为条件根部(条件茬),右上部为判定规则中的各条件项目(条件项),左下部为动作根部(动作茬),右下部为判定规则中的各动作项目(动作项)。
(2)判定规则 判定表的各规则可横向读,也可纵向读。纵向读时,每个判定规则列出条件的某一组合以及该条件组合为真(满足)时采取的相应动作。横向读时,这些规则列出条件的可选取的值以及是否存在要采取的动作。这些判定规则必须包括条件的每一可能的组合。对于动作,则无这样的硬性要求。
(3)条件项目(条件项) 有3种类型的条件项:限定性条件项、扩充性条件项、混合性条件项。
①对于限定性条件项,条件茬指定条件是什么(例如“年龄小于18岁”),而每个规则的条件项只需标识是(真,条件满足)或否(假,条件不满足)或任意(条件满足或不满足均可,可用标记一表示)。
②对于扩充性条件项,条件茬只列出条件的标识(例如“年龄”),不列出其具体值,而每个规则的条件项中列出其具体值(例如“<18”,“18”,“>18”等)。
③混合性条件项是指以上两种表示方法的混合。
(4)动作项目(动作项) 判定规则的动作部分可以是编序的和不编序的两类。对于不编序的情况,在每个规则的动作项中,凡是要执行的动作用指定标记来标识(例如可用标记√来标识要执行),凡是不执行的动作则不加标记。要执行的动作在动作茬处按执行的先后顺序从上向下地列出。对于编序的情况,在每个规则的动作项中,凡是要执行的动作用一个序号来标识(它除表示该动作要执行外还指出其执行的先后),凡是不执行的动作则不加任何标记。由于各个要执行的动作的执行次序已由序号指定,因此在动作茬可按任意顺序来列出各个动作。
6.判定树
判定树是用树状图形来描述或规定与条件组合相结合的各种动作的表达工具。由于判定树这种表达方法十分直观,它更易为人们所接受。图7.3.2-5(b)示出一个判定树,它是对应于图7.3.2-5(a)所示出的判定表(一个计算折扣的判定表)的等效描述。
计算折扣和判定表
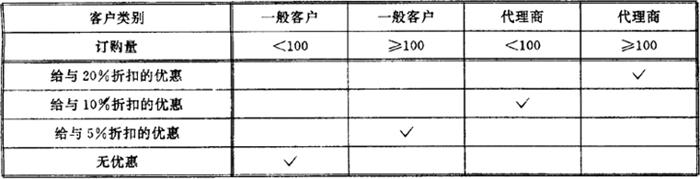
(a)判定表
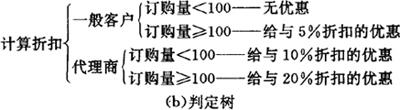
图7.3.2-5 判定表与判定树对照示例